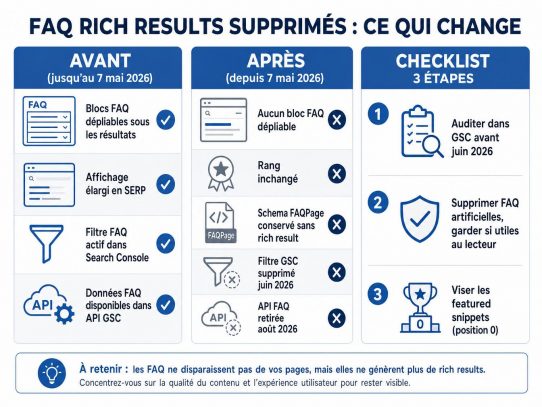

Depuis fin mai 2025, des centaines de sites ont vu disparaître entre 30 % et 90 % de leurs pages indexées en quelques jours, selon les données compilées par Semjuice sur la vague de désindexation Google 2025. Aucune pénalité manuelle, aucun bug de Search Console. Google a méthodiquement nettoyé son index de pages jugées sans valeur : crawlées depuis des années, jamais cliquées ni citées. Si vous lisez cet article, vous avez probablement ouvert votre rapport de couverture Search Console et constaté que quelque chose clochait. Ce guide couvre les causes, le diagnostic et les actions correctives, dans l’ordre où les traiter.
Comprendre ce qui vient de se passer dans votre index
Une désindexation de masse peut avoir deux origines très différentes et les confondre fait perdre des semaines. La première est technique : une directive noindex appliquée par erreur, un fichier robots.txt trop restrictif, une balise canonical pointant au mauvais endroit. Google a alors suivi vos instructions à la lettre. La seconde est algorithmique : Google a décidé, de son propre chef, que vos pages ne méritaient plus de figurer dans son index.
Dans le premier cas, corriger le problème technique suffit souvent à récupérer l’indexation sous 4 à 8 semaines. Dans le second, ajouter une balise ne change rien : c’est le contenu lui-même qui doit évoluer.
L’équipe SEO de Decathlon France a documenté la vague de 2025 avec une approche instructive : malgré des chutes significatives de pages indexées, impressions, clics et ranking sont restés stables sur Decathlon.fr. Les pages disparues étaient celles sans aucun historique de performance. Ce constat change tout à la façon d’évaluer l’urgence.
Ouvrir la Search Console : les trois rapports à consulter en priorité
La Search Console donne un premier diagnostic en moins de 10 minutes. Trois rapports concentrent l’essentiel.
Rapport de couverture d’indexation (Indexation > Pages) : il distingue les pages indexées, les pages exclues et les pages en erreur. Filtrez par statut « Exclues » et regardez les raisons dominantes. « Page avec redirection » ou « Duplicate, Google a choisi une URL différente comme canonique » pointent vers des problèmes de structure. « Crawled – currently not indexed » indique que Google a vu la page mais refusé de l’indexer : c’est le signal le plus fréquent lors des vagues de désindexation liées à la qualité.
Rapport de performance : comparez les impressions sur 3 mois glissants. Si les impressions chutent au même rythme que les pages indexées, les pages perdues avaient du trafic. Si les impressions restent stables, les pages supprimées étaient déjà invisibles.
Rapport d’exploration : il indique si Googlebot visite encore régulièrement votre site et si des erreurs de crawl bloquent des sections entières.
Exportez le rapport de couverture en CSV. C’est la base de travail pour la suite.
Identifier la cause racine : tableau de diagnostic
Chaque raison d’exclusion dans Search Console correspond à un type de problème distinct. Voici les huit causes les plus fréquentes lors d’une désindexation de masse et le premier diagnostic associé.
| Statut Search Console | Cause probable | Premier diagnostic |
|---|---|---|
| Crawled – currently not indexed | Contenu jugé faible ou dupliqué | Comparer le contenu aux pages encore indexées sur le même site |
| Page bloquée par robots.txt | Directive Disallow trop large | Tester l’URL dans le testeur robots.txt de Search Console |
| Page exclue par balise noindex | Noindex ajouté par erreur (plugin, thème, migration) | Inspecter le header HTTP ou le meta robots de la page |
| Page canonique dupliquée (Google a choisi une autre) | Balises canonical contradictoires ou contenu dupliqué | Vérifier les canonicals via Screaming Frog ou Sitebulb |
| Page redirigée | Redirect 301/302 non intentionnel ou chaîne de redirections | Auditer les redirections avec un crawler |
| Erreur 404 / 5xx | Serveur indisponible lors du crawl ou suppression de page | Vérifier les logs serveur sur la période de désindexation |
| Soft 404 | Page vide ou contenu minimal retournant un code 200 | Identifier les pages sous 300 mots sans engagement |
| Exclue par la balise noindex (manuelle) | Action délibérée oubliée ou héritage de l’historique du site | Lister toutes les pages avec meta robots noindex |
Dans le cas d’une mise à jour algorithmique de qualité (comme la vague de juin 2025), la raison dominante est « Crawled – currently not indexed ». Aucune erreur technique : Google a simplement décidé que la page n’apportait pas assez de valeur pour être conservée.
Les causes techniques à corriger immédiatement
Si le rapport de couverture révèle des pages bloquées par robots.txt ou par noindex, agissez avant tout le reste. Ces erreurs masquent les problèmes de fond et faussent l’analyse.
Pour robots.txt : ouvrez le fichier à la racine de votre domaine. Cherchez les directives Disallow trop larges comme Disallow: / ou Disallow: /wp-content/ qui bloqueraient des ressources CSS ou JS nécessaires au rendu. Utilisez le testeur robots.txt intégré à Search Console pour valider chaque URL suspecte. Corrigez le fichier et déposez une demande d’exploration via le rapport de couverture.
Pour les balises noindex : un plugin SEO mal configuré après une migration, un thème qui ajoute <meta name="robots" content="noindex"> sur certains types de pages, une option WordPress « Décourager les moteurs de recherche » cochée accidentellement. Vérifiez dans la Search Console le rapport « Exclue par balise noindex » et comparez-le à ce que vous attendez réellement.
Pour les canonicals : une page qui pointe sur elle-même est correcte. Une page qui pointe sur une version HTTP alors que le site est en HTTPS crée une incohérence. Un article qui pointe sur la page de catégorie parent abandonne son propre potentiel de ranking. Sauvegardez.
Évaluer la qualité du contenu désindexé
Ici commence le travail de fond. Exportez la liste des URLs désindexées. Classez-les par type de page : articles, fiches produits, pages de catégorie, pages de tags, archives. Cette segmentation révèle souvent un pattern clair.
Les pages désindexées par Google lors des mises à jour de contenu partagent généralement plusieurs caractéristiques mesurables : aucun clic en 12 mois dans Search Console, longueur de contenu inférieure à 400 mots, titre identique ou très proche d’autres pages du même site, aucun lien interne entrant, aucune donnée de source primaire.
En pratique, les pages de tags WordPress et les archives de dates sont les premières victimes : elles agrègent du contenu sans en produire et Google les traite comme du contenu dupliqué dilué. La décision la plus efficace pour ce type de pages est souvent noindex délibéré, pas la réécriture.
Pour les articles et fiches produits, la décision est plus nuancée. Avant d’investir dans une réécriture, posez trois questions : cette page a-t-elle déjà généré des impressions dans les 12 derniers mois ? Répond-elle à une intention de recherche spécifique que d’autres pages du site ne couvrent pas ? Peut-elle être enrichie avec des données, une expérience réelle ou une structure que la concurrence n’a pas ?
Checklist de récupération en 11 étapes
Voici l’ordre d’intervention recommandé. Les étapes 1 à 4 sont techniques et résolvables en quelques heures. Les étapes 5 à 11 portent sur le contenu et peuvent prendre plusieurs semaines.
- Vérifier robots.txt : ouvrir le testeur Search Console, tester les 10 URLs désindexées les plus stratégiques, corriger les Disallow abusifs.
- Auditer les balises noindex : lister toutes les pages avec meta robots noindex ou X-Robots-Tag noindex dans les headers HTTP. Distinguer les noindex voulus des accidents.
- Corriger les canonicals incohérents : chaque page doit avoir un canonical qui pointe sur elle-même ou sur la version principale choisie. Zéro boucle, zéro contradiction HTTP/HTTPS.
- Vérifier les redirections : pas de chaînes de plus de 2 sauts. Pas de 302 qui devraient être des 301. Vérifier que les redirections n’ont pas été créées vers des pages elles-mêmes désindexées.
- Segmenter les URLs désindexées par priorité : pages avec historique de trafic (priorité 1) vs pages jamais cliquées (priorité 2) vs pages structurellement vides comme les tags (priorité 3).
- Mettre en noindex les pages sans valeur : tags, archives de dates, pages de résultats de recherche interne, pages de pagination sans contenu propre. Moins de pages faibles dans l’index = meilleur budget de crawl pour les bonnes pages.
- Fusionner les pages proches : si deux articles couvrent le même sujet avec 60 % de contenu commun, fusionnez-les en un seul, plus complet, avec une redirection 301 depuis l’URL abandonnée.
- Enrichir les pages prioritaires : chaque article récupéré doit intégrer des données vérifiables avec source et année, une structure H2 qui répond aux questions PAA (People Also Asked) et au moins un marqueur d’expérience réelle (« On constate que », « En pratique »).
- Renforcer les signaux E-E-A-T : biographie d’auteur avec crédentials réels, date de dernière mise à jour visible, sources citées inline, mentions dans d’autres publications du secteur.
- Soumettre les URLs récupérées : après corrections, utiliser l’outil d’inspection d’URL dans Search Console pour demander l’exploration de chaque page corrigée. Priorité aux pages à fort potentiel.
- Monitorer la réindexation : surveiller le rapport de couverture chaque semaine pendant 8 semaines. La réindexation après correction technique est rapide (1-2 semaines). Après amélioration de contenu, comptez 4 à 8 semaines selon la fréquence de crawl.
Ce que les guides ne disent pas : les faux positifs et les arbitrages
Toutes les désindexations ne méritent pas d’être combattues. La plupart des guides SEO passent cela sous silence.
Si une page a été désindexée et qu’elle n’a jamais généré de trafic, ne figurait pas dans les premiers résultats pour aucune requête et n’a aucun lien interne stratégique, la laisser désindexée est souvent la bonne décision. La réindexer sans l’améliorer envoie un mauvais signal à Google : vous réclamez une place dans l’index sans apporter de valeur supplémentaire.
Sélectionner les pages qui méritent leur place dans l’index de Google vaut mieux que vouloir tout récupérer. Un site avec 500 pages vraiment utiles indexées vaut mieux qu’un site avec 5 000 pages dont 4 500 ne génèrent aucune interaction.
Les mises à jour algorithmiques de 2025 et 2026 ont déplacé la barre de l’indexabilité. Google évalue désormais si une page apporte une réponse que son IA seule ne pourrait pas synthétiser à partir de sources existantes. La valeur ajoutée réelle est devenue un prérequis à l’indexation.
Délais de récupération : ce qu’on peut attendre
Les timings varient selon le type de correction. Voici les fourchettes observées après les vagues de désindexation de 2025.
Une page bloquée par robots.txt ou noindex accidentel revient dans l’index en 1 à 2 semaines une fois la correction déployée et l’exploration demandée via Search Console. Un problème de canonical sur une page bien liée se résout en 2 à 4 semaines. Une page « Crawled – currently not indexed » pour raison de qualité nécessite une réécriture substantielle et un délai de 4 à 8 semaines minimum avant réindexation, voire plus si la fréquence de crawl de votre site est faible.
Pour les sites touchés par une mise à jour core, la récupération complète suit généralement la prochaine mise à jour core ou une mise à jour de qualité dédiée. Google ne réévalue pas les sites en continu sur ces critères : il attend de voir l’ensemble des signaux se stabiliser.
Un index qui rétrécit peut être une opportunité déguisée : celui qui reste.